Anonymisation
Anonymisation is the process of removing personal or private information, such as names, locations, bank account numbers etc. from a document. In the field of language technology, such words or phrases are called named entities (NEs). Removing NEs from a text can be achieved in a couple of ways. They can be substituted by another, similar element: a name is replaced by a different name, a date is replaced by a different date etc. The sentence “David was fired from McDonald’s” could then become “Johnny was fired from Applebee’s”. Another option is to replace these NEs with a label. For example: X was fired from Y, or PERSON_1 was fired from ORGANISATION_1.
Machine Translation
Several tools exist which can anonymise text in different ways. However, what happens when the text is automatically processed afterwards? Let’s take machine translation (MT) as an example.
In case a source text has been anonymised and labels have been added to replace the NE, the quality of the MT output will sadly suffer: no machine translation engine is currently fully able to handle text which includes labels. They are translated in different ways, incorrectly or not at all, making it more difficult for the reader to understand or process the text.
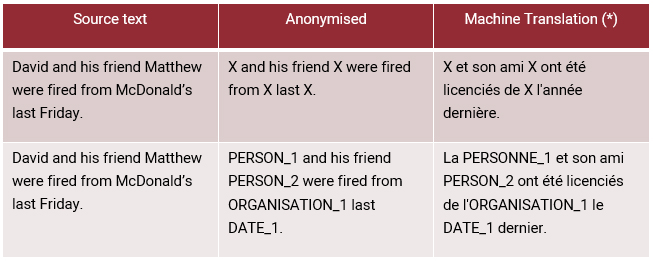
In the first example, the MT engine has incorrectly interpreted the ‘X’, wrongly assuming that this must be a year. Hence, the translation ‘l’année dernière’ (last year) appears, which is nowhere to be found in the source or the anonymised text. If a reader would only read the MT output of the anonymised text, they would misunderstand and misinterpret the meaning conveyed in the source text.
In the second example, the ‘PERSON’-label has been translated once (PERSONNE) but has not been changed the second time it appears. In case the text needs to be de-anonymised (the labels have to be replaced again to reveal the original content), these issues will make the process harder.
On top of these issues comes the fact that the readability of a text will deteriorate when more labels are used: it requires a lot of effort to try and interpret the meaning of a text when important pieces of information are not only missing, but have possibly been mistranslated as well.
Based on these results it might seem that replacing a NE with a similar element is the best option when you want to apply machine translation afterwards. For one thing, it will make a text more readable. On the other hand, this anonymisation strategy puts forward the issue of inflection. When there is a misfit between a replaced name and a pronoun, the quality of both the anonymised text and the machine translation is affected.

In this example, the male name ‘David’ has been anonymised and replaced by the female name ‘Julia’. The original text referred to ‘his friend’, which is causing a grammatical issue in the anonymised text, which is then again taken over by the machine translation output: ‘zijn vriend’.
In short: a lot of research is still needed in order to construct a machine translation system that is fit to translate anonymised sentences. But how about using anonymisation in the process of building the machine translation system in the first place?
Training data
In order to train a machine translation engine, a large volume of data is required. The question that automatically follows this statement, is how safe it is to build engines based on data which contains sensitive information. CrossLang has been building custom machine translation engines for years and has often used customer data in this process.
First of all, the risk that sensitive information is leaked or that the MT system will produce personal information in and of itself, is extremely low. When an MT engine is trained, the data is first segmented into sentences. These sentences are then scrambled, making it impossible for an attacker to glue the various pieces of information back together. This means that if you train an engine based on sentences which include your address, for example, you do not need to worry that your address will be linked back to you or will randomly appear in the output.
Despite this, many companies or agencies are, understandably, very careful when sharing large volumes of sensitive data. That is where anonymisation can play a big part. Data can be anonymised before it is used in order to train an engine. This will lower the risk of data breaches even further. The downside is that this can also negatively affect the performance of the machine translation system, as certain pieces of information may be lost in the anonymisation process.
Research
The introduction of GDPR in 2016 caused a huge shift in the way in which data safety and personal privacy is viewed in the European Union. Partly because of this change, we have seen an increase in the research into anonymisation. Although great efforts have been made, there are still a lot of interesting aspects in this field that can be investigated further. CrossLang carried out an assessment on anonymisation in the ELRC action of the European Commission in 2022. The full report can be downloaded here.

