What is a custom machine translation engine?
Machine translation has become an integral part of our daily lives, with popular platforms like Google Translate and DeepL offering generic translation services. These engines have been developed using publicly available, mostly generic data. This means that they are trained using texts from varying sources and include many different subjects. However, it is also possible to train an engine for a specific topic, style, or jargon. These are called custom machine translation engines.
Why is a custom machine translation engine important?
Generic machine translation engines are a useful tool when it comes to translating texts and documents. But can any content type simply be translated by any engine? If only it were that simple. Generic engines will often fall short when translating industry-specific jargon or highly specialised content. Although machine translation quality is increasing, translating technical, legal or medical texts remains a pressing issue.
By developing a custom engine, businesses can ensure accurate translations for their content, resulting in improved quality and efficiency. Especially when large amounts of data in the same field need to be translated, building a custom machine translation engine is definitely worth the investment.
Are custom machine translation engines publicly available?
Although generic machine translation engines are probably more known by the general public, many custom or domain-specific machine translation engines also exist. For example, CrossLang has developed an engine called judicio, which has been trained on publicly available legal data.
Custom engines are predominantly built for organisations or private businesses in the medical, automotive, or public sector. However, they are not publicly available as they are trained using the customer’s proprietary data.
The 5-step process of building a custom machine translation engine
With more than twenty years of experience in the translation automation business, CrossLang’s team of linguists and machine learning experts have developed a streamlined process towards building a custom machine translation engine from scratch.

1. Requirement Analysis
The first step in building a custom machine translation engine is closely examining your project’s unique requirements. What exactly will the engine be used for? Who will use it? Which language pairs are needed? What is the industry domain? What is the desired output quality? What are the requirements in terms of style and terminology? Based on the answers to these questions, our team of linguists and NLP experts starts mapping out the various possibilities.
2. Data collection and pre-processing
Building a custom machine translation engine requires large volumes of specific data. This data should be relevant for the field for which the engine is being developed, also known as in-domain data. For example, if you are building a medical engine, you could use lots of package leaflets or medical devices manuals.
The primary resources for building custom engines are bilingual data sets, comprising a source text and its corresponding human-translated version.
Once enough data has been collected, it still needs a lot of pre-processing with the help of a team of specialized language engineers and experts. This is crucial, as high-quality data plays a significant role in the performance of the custom machine translation engine. This process includes, among other things, deleting duplicate sentences, removing irrelevant data, and checking if all the translations exactly match the correct source sentence.
3. Engine training
A machine-learning model processes all the collected data and builds the machine translation engine. The model uses the provided data as examples and learns the patterns and relationships between the source and target languages. The goal is to fine-tune the model until it can accurately and efficiently translate new content that it hasn’t seen before.
Custom engines are designed for continuous re-training and improvement. As more translated or post-edited content becomes available, it can be fed back into the system, refining the engine’s performance over time. CrossLang can also establish a feedback loop with the help of end users, enabling them to report issues and provide improvement suggestions.
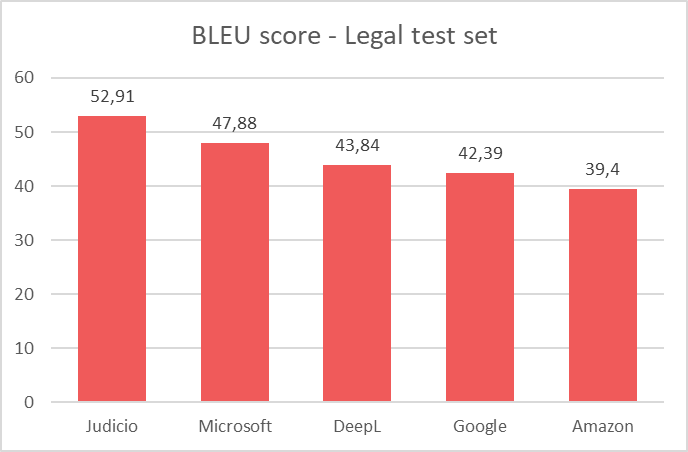
4. Automated evaluation
After the training, the new engine is evaluated using automated metrics (such as BLEU, TER, METEOR etc.). These metrics help us gain more information about the quality of the model that has been built. It is also useful to compare the engine that was built to a couple of generic engines to assess whether it scores better for the types of content it is intended to work for.
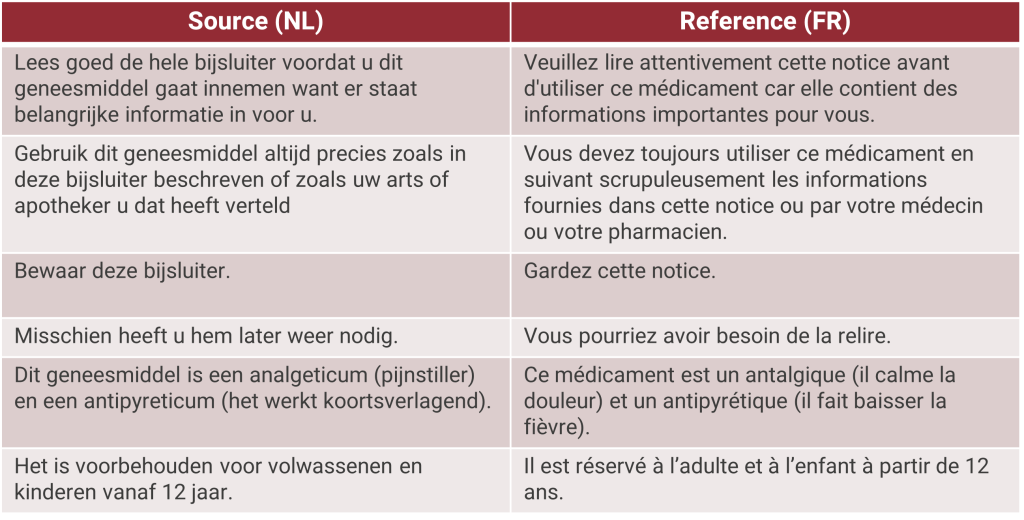
5. Human evaluation
In the final step, linguists experienced in the specific domain conduct a human evaluation. This evaluation helps us establish the usability of a machine translation engine in real-life scenarios and helps identify problems that an automated evaluation may miss. An evaluation can be carried out to test the productivity or the quality of the new engine. Using the CrossLang MT Evaluation Tool, various tests can be set up such as measuring the time saved compared to generic engines or ranking the output quality of different engines.
How can you access custom machine translation engines?
There are various ways in which customers can access their newly built engine. The CrossLang MT Gateway, with its translation interface, allows users to translate texts or documents. However, CrossLang is able to integrate the custom engine into our customers’ software or TMS (e.g. XTM, SDL or MemoQ) as well, thus maintaining and optimizing their existing localization workflow. Our team of engineers and language experts is always available to provide continuous support, maintenance and consultancy.
Getting started
Do you think a custom machine translation engine might be a great addition for you and your business? Contact us for more information.

